The short version of what I’m about to write is that this web site is running on a new web server, which should mean the site will be running faster than ever before. If you see any problems on the site, please contact me so I can fix them. For those interested, I am including more details below.
I am grateful for all the users of this site, and hope everyone who has visited has benefited in some way when they’ve come to the site. This web site has been around since 2010, when it was originally launched as a Blogger site. Back in 2013 I moved the site to self-hosted WordPress, which allowed me to expand the site’s content and functionality, but also meant I had to maintain the site and had to deal with the fact that many other sites were running on the same server. My web host was actually great, and I continue to run other sites on the same host without any problems, but they had no good solution for moving this site to a bigger server when it needed it.
 When I created the B&F Compendium of Jewish Genealogy, I stretched the capacity of the server to its limits. The average WordPress site only has a few Pages (as opposed to Posts, of which there can be many), maybe a few dozen, but the Compendium uses over 25,000 Pages and is continuing to grow. Whether WordPress was the right platform to develop the Compendium on is a different question, but as I had it running in WordPress I had to find a way to increase the capacity of the server without breaking the bank (since this site is a labor of love, and I make no money from it).
When I created the B&F Compendium of Jewish Genealogy, I stretched the capacity of the server to its limits. The average WordPress site only has a few Pages (as opposed to Posts, of which there can be many), maybe a few dozen, but the Compendium uses over 25,000 Pages and is continuing to grow. Whether WordPress was the right platform to develop the Compendium on is a different question, but as I had it running in WordPress I had to find a way to increase the capacity of the server without breaking the bank (since this site is a labor of love, and I make no money from it).
For those who use WordPress, think about the fact that on the WordPress editor page, all Pages are loaded into a drop-down menu for selecting a parent page. Imagine now that you have 25,000 pages and that the menu is obviously part of the page that loads.
 Over the past several months I’ve been working to move my site to a service operated by Amazon called Lightsail. Lightsail is essentially a simplified version of Amazon’s EC2 cloud computing service. You pay a set amount a month and get a VPS server that you control. For $5 a month you get a Linux server with 512MB of RAM and 20GB of storage, and the best part is that you can easily upgrade the server if you need more power. The $5/month is more than I paid before, but it’s still quite reasonable for the added power I get, and if I need to I can move to a more powerful server for simple increments in cost.
Over the past several months I’ve been working to move my site to a service operated by Amazon called Lightsail. Lightsail is essentially a simplified version of Amazon’s EC2 cloud computing service. You pay a set amount a month and get a VPS server that you control. For $5 a month you get a Linux server with 512MB of RAM and 20GB of storage, and the best part is that you can easily upgrade the server if you need more power. The $5/month is more than I paid before, but it’s still quite reasonable for the added power I get, and if I need to I can move to a more powerful server for simple increments in cost.
Migrating a web site to a new server is never easy, and not to be taken lightly. There are always unexpected problems, and my site had some fairly unique problems. One of the problems I ran into was that the database that holds all the information for the site was so large that it was difficult to even export to a format I could move to the new server. At first the exported database was over 300MB. I looked into the database and saw a lot of the records had to do with plug-ins I used. I had to disable those plug-ins, and remove their data from the database manually, which brought the size down to a still difficult 100MB. When I was finally able to export the database, I found it impossible to import to the new server. The web interface to the database, which was the easiest way to import the data, would run out of memory before completing the import. I tried uploading the file to the server directly and importing the data via the command line, but still had trouble.
Eventually I found a great little piece of code that helped me import the data by breaking it down into smaller chunks and importing it piece by piece (BigDump, which I recommend highly for those who need to import large databases). However, even with this new tool I ended up with an error message I didn’t understand. After asking for help online, I found out that the error was due to the original web site running on an older version of the database software (MySQL) and that the newer version didn’t allow a date field to be empty (set to 0 essentially). When you had a data field in the database that you didn’t have a value for, it was supposed to be set to Jan 1 1970 instead. Go figure, but I had 53 times in the database where I had a zeroed out date, and doing a find and replace in the database fixed the problem and the database finally imported.
Other problems were more mundane. As I tried different parts of the site, I noticed certain things didn’t work properly.
The contact form didn’t work, which it turns out was because the new server didn’t handle mail the same way as the old server. After re-configuring the mail, the contact form began to work.
The maps on the Compendium city pages were not being displayed because for some reason Google thought this was a different site. After setting up new credentials for the the Google Maps API, the maps began to work again as well.
The more insidious problems had to do with file and folder permissions. Having moved much of the files over from my old server, the file permissions on many things were wrong. Now I find file permissions in UNIX to be a form of the dark arts, but slowly I’ve been fixing the problems. I noticed, for example, that I couldn’t upload new images, which is because the server couldn’t create a new folder to upload images to for this month. Sure enough, it was a permissions problem. Upgrading plug-ins has also been difficult due to permission issues. This is probably an issue that will continue to cause issues for some time until I’ve worked out all the bugs.
For the last few days the site has been running completely on the new server. I imagine there will still be problems going forward, and I ask that if you run into anything you think is weird on the site, please please contact me and tell me what you saw. As with the above examples, the problems can be hard to predict, so if you see something odd, such as an error message, or even a missing image, don’t assume I already know about the problem. Please contact me and let me know, so I can fix it for everyone.
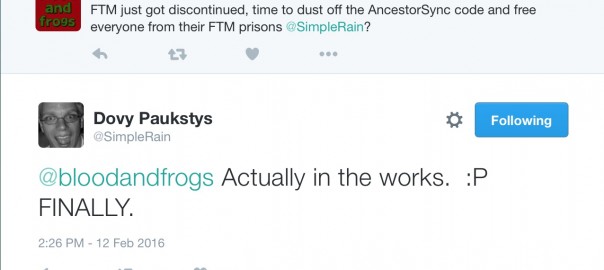
 It’s certainly an interesting story about Ancestry
It’s certainly an interesting story about Ancestry