
 While making my plans for the upcoming IAJGS International Conference on Jewish Genealogy in Warsaw, I came up with an experiment I’d like to try. This experiment needs dozens, if not hundreds, of volunteers to pull off successfully.
While making my plans for the upcoming IAJGS International Conference on Jewish Genealogy in Warsaw, I came up with an experiment I’d like to try. This experiment needs dozens, if not hundreds, of volunteers to pull off successfully.
The short version is I’m organizing volunteers to photograph and geocode all the gravestones in the Okopowa St. Cemetery in Warsaw, and then upload those images to both BillionGraves as well as to special groups on Flickr when they will become available to everyone to use.
There are probably over 80,000 gravestones in the cemetery, and while I don’t expect we’ll be able to get to all of them by the time the conference ends, the simple effort to do so will be an incredible experiment in collaborative genealogy.
For full details on this experiment, and how to get involved, please go to the Okopowa St. Project page.
As of August 31, 2018, I’ve moved the original text of the Okopowa St. Project page to this post, so we can keep it for future reference. The Okopowa St. Project page itself will continue to point to all related articles, and give the status of the project as we seek to improve the collection of genealogy data in cemeteries.
Original Project Text:
An experiment in collaborative genealogy
Like many people planning to attend the upcoming IAJGS International Conference on Jewish Genealogy in Warsaw this August, I’ve been trying to figure out my schedule, see when I’ll be at the conference, and what else I can do to take advantage of the fact that I will be spending a week in Warsaw, Poland.

One place I have been planning to visit is the Okopowa St. Cemetery, which I last visited 25 years ago while visiting Poland as part of the March of the Living. Most of the photos from my popular article Jewish Gravestone Symbols come from the Okopowa St. Cemetery, and I’ve long wanted to re-visit it.
The Okopowa St. Cemetery is one of the largest Jewish cemeteries in the world, and certainly is the largest surviving cemetery in Poland. As I contemplated my visit I realized that there was an opportunity to attempt something that might not be possible again any time soon. What if large numbers of conference attendees, many of who may already be planning to visit the cemetery, could collaborate in documenting all the gravestones in the cemetery? BillionGraves only has 226 photographs for the entire cemetery. Yes, I know there’s an excellent database on the Foundation for Documentation of Jewish Cemeteries (FDJC) site for the Okopowa St. Cemetery.
In the end, if we’re lucky, we’ll have geocoded high-resolution photos of all the graves, and the photos will be available for everyone to use in whatever projects they want to use them in. If the FDJC wants to add these photos to their site, they can. If JOWBR wants to include them, it can also do so. I’ve set up a series of steps, outlined below, which will make these photographs accessible and useful to the most people. If this succeeds, I hope people will use this model for other genealogy projects.
Some of the things I’m hoping to find out include if the tools are the best ones to accomplish these tasks, if leaving the groups open to all, and the Google Sheet editable by all, works, or if people will abuse those freedoms. Is it too complicated to upload photos to two different sites? This will be a learning experience, whose lessons we will be able to apply to future projects.
![]() Here’s how this will work. Volunteers will install two apps on their smart phones – BillionGraves and Flickr. They should also make sure they have accounts set up for both BillionGraves and Yahoo (the owner of Flickr), and configure the apps so that they are connected to their accounts. For BillionGraves, make sure to have the Save to Camera Roll option selected in your preferences if you use an iPhone. You’ll need that later to allow you to upload the photos to Flickr.
Here’s how this will work. Volunteers will install two apps on their smart phones – BillionGraves and Flickr. They should also make sure they have accounts set up for both BillionGraves and Yahoo (the owner of Flickr), and configure the apps so that they are connected to their accounts. For BillionGraves, make sure to have the Save to Camera Roll option selected in your preferences if you use an iPhone. You’ll need that later to allow you to upload the photos to Flickr. ![]() For Flickr, log into your account on the web and set the default license to “Attribution-ShareAlike Creative Commons”. This is important, as it will allow these images to be used by anyone who wants, but still requires them to attribute the photograph to you.
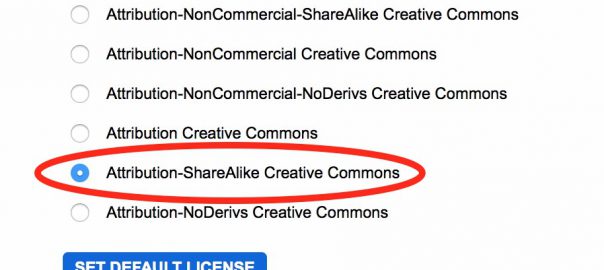
For Flickr, log into your account on the web and set the default license to “Attribution-ShareAlike Creative Commons”. This is important, as it will allow these images to be used by anyone who wants, but still requires them to attribute the photograph to you.
Volunteers will choose one section to photograph (larger sections will need multiple volunteers). There is a Google Sheet to coordinate volunteers. Take a look and add your name to a section. The volunteer should join the group on Flickr for the section they’ve chosen (the links to those groups are in the Google Sheet, and below). For larger sections with many volunteers, the volunteers should use the discussion area of the group on Flickr to figure out when they will be photographing, and try to divide up the work.
When volunteers go to the cemetery, they will go to the section they’ve selected, and photograph all the graves in that section, or whatever part of it they can. They will photograph the graves using the BillionGraves app, and upload all the images to the site (this can be done later at the hotel using the free WiFi. In this first step, all the photos will be accessible via BillionGraves. In addition, when you’re done, you will go to the Flickr app and upload your photos to Flickr, and when they’re on Flickr, you will then share them to the appropriate group for the section they were taken in. You should then go to the discussion area for that group, and post how many photos you’ve shared to the group, if it was all of the graves, or if there is still more work to be done (and to the best of your ability describe what areas still need to be photographed).
At this point, if you want, you can delete the photos from your phone. Make sure, however, that the photos have been uploaded to both BillionGraves and Flickr before deleting them.
Let’s go over this once more, in clear order:
Before going to the cemetery:
Join our Facebook group Okopowa St. Project to discuss the project, and share your experiences with other volunteers.
Set up BillionGraves:
- Set up an account on BillionGraves. If you already have an account on BillionGraves, login through this link so they know you’re involved in this project.
- Sign up for the BillionGraves Event for this project.
- Download the BillionGraves app for iPhone or Android.
- Connect the BillionGraves app on your phone to your account.
- If you use an iPhone, go to Preferences in the BillionGraves app on your phone and turn on ‘Save to Camera Roll’.
Set up Flickr:
- Set up a Flickr/Yahoo account.
- Set your default license for photos to “Attribution-ShareAlike Creative Commons”.
- Download the Flickr app for iPhone or Android.
- Connect the Flickr app on your phone to your account.
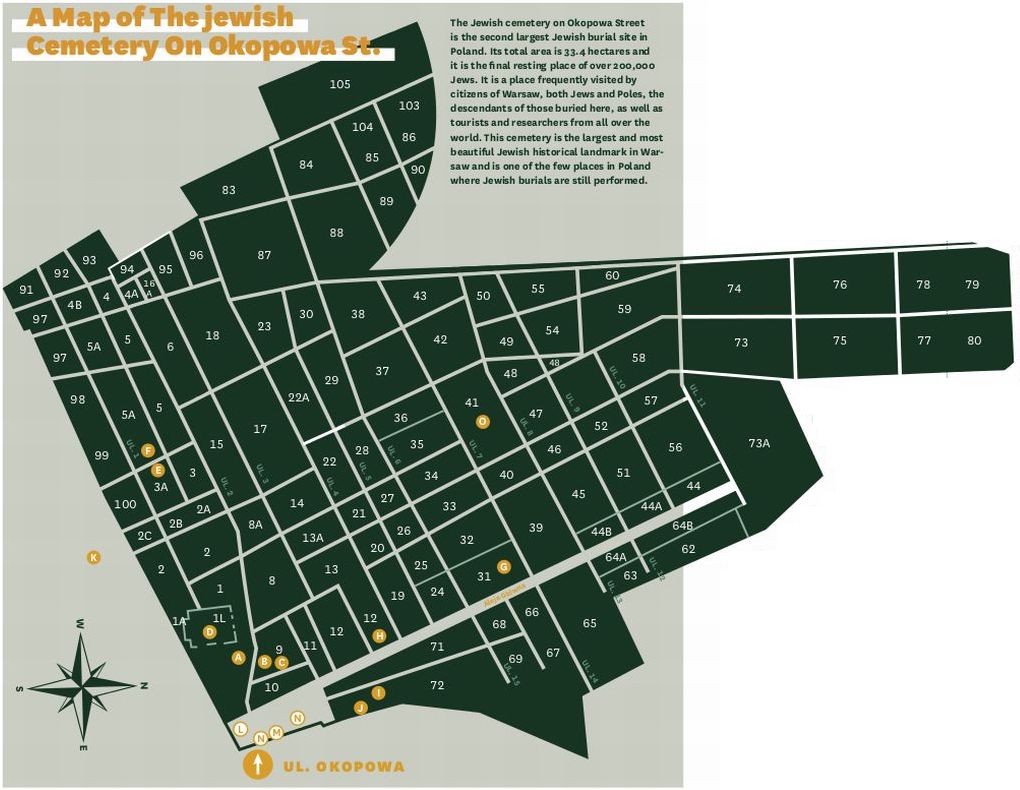
Select a section to photograph:
- Look at the map above (click to zoom in) to get an idea of where the sections are in relation to the entrance, and how big they are.
- Go to the Google Sheet and see which sections already have volunteers. Select a section that has no volunteers and add your name in the left-most volunteer cell for that section.
- Click on the section name in the Google Sheet, or find it below, and go to the Flickr group for that section and join it. All discussion for that specific section will take place in the Flickr group.
- In the Flickr group, post an introduction in the discussion list, and explain when you plan to photograph the section.
- Print out a copy of the map, and circle the section you will be photographing. Make sure to bring it with you to Warsaw.
Preparing to go to the cemetery:
- Double-check that BillionGraves is properly configured.
- Make sure you have enough room on your phone to fit all the photos you’re about to take. If you need to clear up your phone to make room, do so.
- Charge your phone fully. If you have an external battery, make sure that it charged as well and bring it with you. You don’t want to be in the middle of a section and have your battery die.
- Check the group on Flickr for your section, and see if there is any discussions you missed. Did someone already photograph that section? Is there part this is incomplete? Check before you go because you may or may not have Internet in the cemetery.
- Bring paper and pen so you can take notes, sketch the layout of the section if you want, etc.
- Make sure to wear pants and appropriate shoes. The cemetery is overgrown, and you don’t want to hurt yourself.
At the cemetery:
- When you arrive at the cemetery, make your way to your section, and figure out an appropriate path to photograph all or as many graves as you can. Take extra photos that show the paths, the lines of gravestones, whatever. You can take these photos using your standard camera app.
- Make your way to each gravestone, and take multiple photos of each. Get one that shows the whole gravestone, and another that frames just the text on the stone. If you think you need more than one photograph of the text for it to be clear, take more than one. Don’t limit yourself. Check the back of each grave in case there is more text.
After the cemetery:
- Upload your photos to BillionGraves. Try to group the photos of each grave together. Skip the general photos of the area, as those are not useful for BillionGraves. Make sure all the photos fully upload to BillionGraves before leaving the app.
- Upload all your photos to Flickr, and then Share them to the appropriate group for your section. If you photographed more than one section, make sure to upload the photos to their appropriate sections. Make sure everything fully uploads before leaving the app.
- Post to the Flickr discussion area for your section’s group and explain how many gravestones you photographed, how many photos you uploaded, and if there is anything more for others to photograph. Do this even if you’re the only person in the group, as it will be there for future reference. You can even post immediately after taking the photos, and then follow up after you upload them (in case there’s a significant gap between those events). That will keep everyone informed as to what is going on.
The table showing the links to the Flickr groups for each section is below. I hope if you’ve made it this far, you are considering joining this collaborative effort.
Thank you.
For photos that are not in one of the above sections, there is a general group for this project here.





{kind=link}