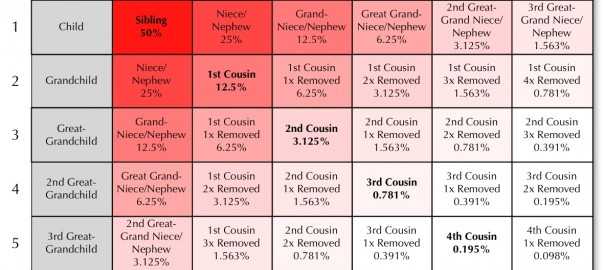
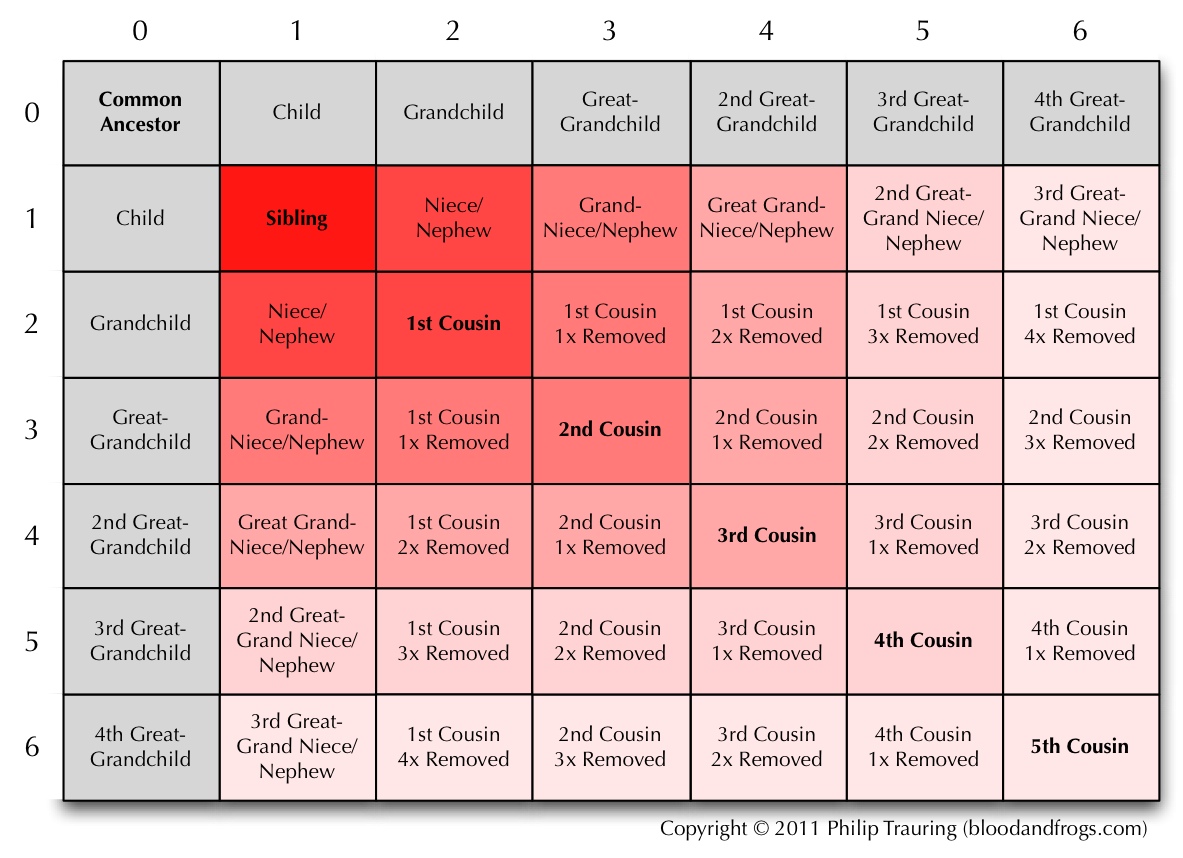
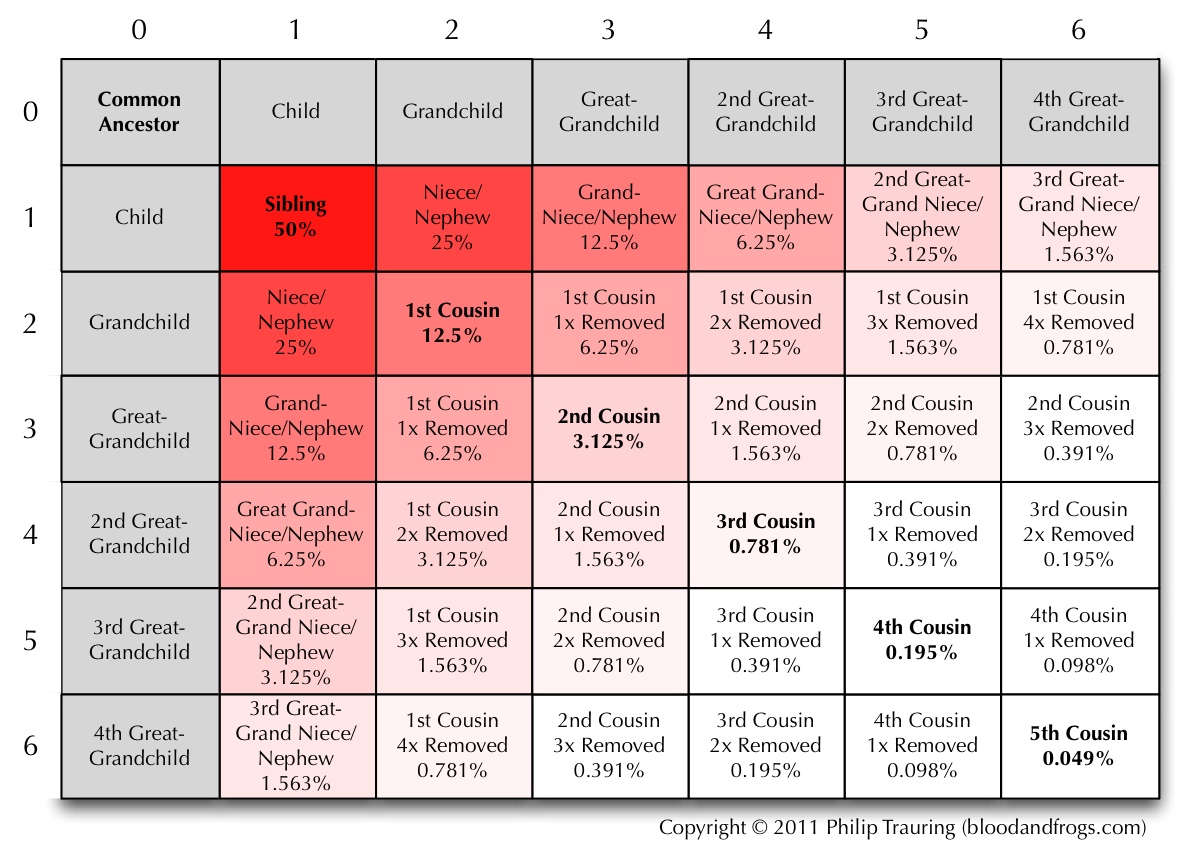
Over a year ago I took a look at genealogy data standards and where they were headed in my article The Future of Sharing (Genealogical Data). In some ways a lot has changed since I wrote the article, but in some ways we’re really at the same point we were then, with no clear picture of the future. This past week’s 2nd annual Rootstech conference (my last article mentioned the then-upcoming 1st Rootstech) has brought some of the questions asked into focus, so I thought it was worth reviewing what has happened.
GEDCOM X
 On the face of it, the biggest news to come out of the conference was the release of long-awaited successor to GEDCOM, GEDCOM X. FamilySearch, the online presence of the LDS church which was the creator and maintainer of the original GEDCOM standard, released this new standard at the conference a few days ago. FamilySearch hits a lot of the right keywords in the release – the format can be XML or JSON based, is released under an Creative Commons license, supports metadata including Dublin Core and FOAF, the development is hosted on Github, it offers both a file format (like tradition GEDCOM) and an API, and more. Yet there are also some strange decisions that seem to have been made, and no explanation seems to be given. One that stands out is the decision to base the file format MIME, a format created for sending e-mail attachements (MIME is an acronym of Multipurpose Internet Mail Extensions). So far the logic behind many of the decisions that have been made seem very opaque. The entire development of GEDCOM X seems to have been done up to this point without any input from the industry at large, or even the well know efforts to improve GEDCOM, such as the Better GEDCOM group. Indeed, the answer in their FAQ about these efforts seems largely patronizing:
On the face of it, the biggest news to come out of the conference was the release of long-awaited successor to GEDCOM, GEDCOM X. FamilySearch, the online presence of the LDS church which was the creator and maintainer of the original GEDCOM standard, released this new standard at the conference a few days ago. FamilySearch hits a lot of the right keywords in the release – the format can be XML or JSON based, is released under an Creative Commons license, supports metadata including Dublin Core and FOAF, the development is hosted on Github, it offers both a file format (like tradition GEDCOM) and an API, and more. Yet there are also some strange decisions that seem to have been made, and no explanation seems to be given. One that stands out is the decision to base the file format MIME, a format created for sending e-mail attachements (MIME is an acronym of Multipurpose Internet Mail Extensions). So far the logic behind many of the decisions that have been made seem very opaque. The entire development of GEDCOM X seems to have been done up to this point without any input from the industry at large, or even the well know efforts to improve GEDCOM, such as the Better GEDCOM group. Indeed, the answer in their FAQ about these efforts seems largely patronizing:
Have you heard about FHISO (BetterGEDCOM), OpenGen, ?
Of course. We’ve heard about them and many others who are making efforts to standardize genealogical technologies. We applaud the work of everybody willing to contribute to the standardization effort, and we hope they will continue to contribute their voices.
In other words, at least to my ears, it’s saying they know other people want to improve GEDCOM, but they are going to do their own thing and maybe they’ll listen occassionally (but no promises). In short, while it’s great that FamilySearch has come out with a new standard, their approach to doing so does not seem geared towards gaining widespread adoption from the industry at large, or at least not in such a friendly manner.
Of course, the huge advantage FamilySearch has over just about anyone else is the very large developer network they’ve cultivated for accessing familysearch.org. They are essentially a non-profit organization which has many commercial companies using their current API. To the extent that they transition these existing companies from their legacy API to GEDCOM X, they will certainly have a major advantage over other efforts to replace GEDCOM.
Progress On Other Fronts
So what happened to the other efforts mentioned in my last article?
The most visible effort has been the BetterGEDCOM wiki, which is moving from an informal group to a formal organization called the Family History Information Standards Organisation (FHISO) which will now sponsor the wiki. While they have been the most active effort to create a replacement for GEDCOM, they seem to have been overtaken by the too-many-cooks problem and how they plan on coming to a consensus remains to be seen, let alone how they convince industry organizations and companies to agree with them. It will be interesting to see FHISO’s response to GEDCOM X, and if they will focus their efforts on trying to implement their ideas within the GEDCOM X framework, or if they will continue to try to go it alone.
The OpenGen International Alliance, started by the people at AppleTree.com, doesn’t seem to have taken off. Either for the matter has AppleTree, which may explain the why the OpenGen site hasn’t been updated in the past year (and refers to an upcoming webinar last March).
APIs
One of the most interesting developments last year was the introduction of Application Programming Interfaces (APIs) for genealogy web sites. Indeed, the rumors around what would become GEDCOM X was that it was only an API, and not a file format, but luckily that turned out not to be true and it is both. The only APIs that had been released before my last article were Geni.com‘s API and OneWorldTree.com‘s GenealogyCloud API.
Geni seems to at least gotten some traction with their API, with future support for syncing data coming from AncestorSync. Presumably this uses Geni’s API. I haven’t heard of other uses of the Geni API, however. If you know of other developers using the Geni API, let me know in the comment.
I have not heard of anyone using the GenealogyCloud API. If you know any anyone using GenealogyCloud, let me know in the comments.
As I predicted in the last article, MyHeritage introduced their own API, smartly named Family Graph. I say smartly because it is clearly mimicking Facebooks’ Social Graph API. They’re not comparing themselves to Geni, but to Facebook, which is smart. The other very smart thing they did was introduce a contest to develop applications that use the Family Graph API. If no one uses your API, what’s the point right? The winner receives $10,000. The deadline for that contest is actually in about a week from now, with judging by a panel taking place in the first half of March and the results announced on March 15th. The real test will be the quality of the applications submitted, and whether the applications were submitted by individual developers or by larger companies. If the contest results are published next month with no major applications, then this will in my estimation be a setback for MyHeritage, not an achievement.
Conclusion
It will be very interesting to see how the introduction of GEDCOM X is accepted by the genealogy companies at large that are needed to make a new format successful. FamilySearch has some key advantages in that they are a non-profit organization (even though in many ways they compete with the large commercial companies like Ancestry.com and MyHeritage.com) and that they already have a large developer network. While many of the largest genealogy companies are not currently part of that developer network, if all of the ones who are start adopting GEDCOM X as their export format of choice, I think it will be hard for other companies to not adopt it. GEDCOM X’s dual format/API functionality also gives it a major edge, especially if FamilySearch’s legacy API is replaced by the API functionality in GEDCOM X.
Some have predicted there would never be a true replacement for GEDCOM, and others have said that technology such as AncestorSync’s upcoming products would make the need for a file format unnecessary. I think both of these assertions are incorrect. There will be a replacement for GEDCOM, and it is necessary. Whether or not GEDCOM X is the ideal replacement seems to me to be a moot point. They will get the traction they need to push GEDCOM X into the mainstream. The real question is will they truly make it an open standard, or will they continue to hold it close to the chest? The real test will be when other groups insist on various features, and how they handle those demands. FamilySearch has put in all the trappings of an open and transparent development process, so let’s hope they keep in that direction.