Thank you to Geneabloggers for pointing out it’s my second blogiversary today. Thank you also to Jim Sanders from Hidden Genealogy Nuggets for pointing out to me that they did so.
Blood and Frogs: Jewish Genealogy and More was started on November 25, 2010. It’s been a fun time, and I hope people have enjoyed what I’ve written and done here. If you’ve liked a specific article or site feature, please let me know in the comments.
In the past year I’ve also been working on two other sites, which unfortunately has lowered my output on this blog. I hope the usefulness of these two sites makes up for my lowered output on this blog.
The first, now almost a year old, is genealogy.org.il, the web site of the Israel Genealogy Research Association (IGRA). It has already been ranked one of the top 40 international (non-US) web sites by Family Tree Magazine. Watch genealogy.org.il in the coming weeks for the introduction of one of the most advanced record search engines of any genealogy site – to support the over 50 databases added to the site in the past year.
The second is not yet done, but will be launching soon. I will writing about it here when the new site is ready. It is a site built to focus research into the Jewish community of a single town, Kańczuga, Poland (from the former Austro-Hungarian district of Galicia). There have not been any Jews in Kańczuga since 1942 when the Nazis murdered the entire Jewish population there, but there are many descendants of Jewish people who lived there prior to the Holocaust, and this site will lead research into the community that existed there, and try to make connections between long-lost relatives whose families came from the town.
Thank you to all my readers, to my 2601 followers on Facebook, and to my 386 followers on Twitter.
One year ago today I started this blog. It seems like a lot longer. So much has happened in the past year, that I thought I would share a bit of my experiences from the past year, and point to some of the articles and features I’ve added to this site that I’m most proud.
My first post one year ago asked the question of whether I should switch from the genealogy program Reunion, which I’ve used for more than 15 years, to the then recently introduced Mac version of Family Tree Maker (FTM). At the time, I didn’t feel it made sense. Since then I’ve actually taken part in beta testing the next version of FTM for the Mac (due out any day now, currently in pre-sale for 20% off). They’ve added the incredible feature of syncing your tree with an online tree on Ancestry.com. There are still some issues that may prevent me from switching, but they are definitely moving in the right direction. The one missing feature that may seem minor, but which just means a lot of work for me to switch (and heck, I’m lazy), is the ability to virtually crop photos when displaying them on a specific user’s profile. For example, you can use one family photo that has ten people, and crop a headshot for each family member from the single photo (without having to actually crop the photo in another program). I’ll hold judgement until the final version is released soon, however.
In preparation for that lecture, I also created an index browser for the one of the record sets I discuss, located at the Felix Archives in Antwerp. This was quite a lot of work, linking over 5,000 index page images (showing over 10,000 pages) to the images on the Felix Archives website (which is in Flemish only).
The updated information provided in that lecture then formed the basis of a forthcoming article in the journal AVOTAYNU: The International Review of Jewish Genealogy. One thing I’ve learned in publishing in the print format, compared to publishing online, is that there’s a limit on space. Maybe I’d be a better writer if I was always limited in how much I could write, but I like being able to use as many illustrations as I want online. While I will probably post a more detailed and updated version of my original second-day article to this blog, for the moment I have a page (tab also above) with all the links and resources mentioned in the lecture and article kept up to date.
In addition to the index browser I put together for my lecture, I also created several other unique resources on my site over the past year.
Some of my most popular resources are the PDF Forms I created. These genealogy forms include an Ancestor Form (Pedigree Chart), Family Form, Sibling Form, Ancestor Location Form, and the very unique US Immigrant Census Form. What is unique about all of these forms, is that they are fillable on the computer, can be printed in Letter or A4 sizes, text entered into a field that is too long for the field will shrink to fit, and the forms can be linked to each other. Forms are linked, for example, when you fill out an Ancestor Form and want to add the siblings of the source person’s parent, you just fill out a Sibling Form and write the number of the sibling form next to the name of the parent on the Ancestor Form. These forms are intended for those new to genealogy, but also for experienced genealogists who want to use them to collect information from other relatives. The US Immigrant Census Form is useful to anyone doing research on immigrants who arrived in the US between 1860 and 1930. For more information on all of these forms, go to the Forms page (also a tab on the top of all pages of my blog).
Another popular resource is my page on US Naturalizations. Besides discussing different options for retrieving US naturalization papers, I also provide the list of records available from the National Archive through their electronic ordering system. Normally you need to log into their system and start filling out the form to order before you can see what is available. My page tells you what years records exist for through the various locations around the US.
One of the features that doesn’t get a lot of notice, but which I spent a considerable amount of time developing, is my B&F Enhanced Search Engine. Inspired by the Mocavo genealogy search engine, I created my very own search engine using Google tools, and it is very good at finding genealogy records connected to names you enter into it. It also has an additional benefit for people searching for information from towns in the former Austrian province of Galicia, in that it will automatically expand town names so variants of the town names are also searched. The reason it is only for Galicia is that Google restricts how many of these substitutions you can use, so I picked a small region to test it out. If you have family from Galicia (like all of my father’s family) you’re in luck.
Most Popular Articles
The five most popular articles on this blog in the past year were:
The most interesting thing about that list is each article is very different.
The first article, explaining how to retrieve copies of Jewish vital records from Poland, was a surprisingly popular article. It is very long, and perhaps no one had gone into that much detail on the notoriously different process of ordering records from Poland before. That article has also been published in print, over two issues of the Pineles Genealogist (actually more accurately half has been published, the other half coming in the next issue). I was also asked to publish a modified form of this article in another genealogy journal, but unfortunately did not have to the time to make the changes necessary.
The second article is a guide to Jewish genealogy mailing lists, on JewishGen, Rootsweb, Yahoo, etc. It is an attempt to be a comprehensive list of mailing lists of interest to Jewish genealogists. This article is one of several ‘Basics’ articles I’ve published in the past year, trying to help people get started in genealogy. Other ‘Basics’ articles include an article on the JewishGen Family Finder (critical for Jewish genealogy), Ancestral Towns (Shtetls), and the more general Historical Newspapers and Up, Down and Sideways (a look at researching through collateral relatives). In addition, I have guest-published a series of articles on the JewishGen Blog, called JewishGen Basics, which take a detailed look at some of the more important features of the JewishGen website. Some of these articles are expansions of articles that originally appeared on my own blog.
A very popular article, and something that seems to get consistent traffic, is my article on Jewish Gravestone Symbols. It is a very visual look at many of the symbols used on Jewish gravestones, based on a set of photographs I shot almost twenty years ago while in Poland. I was going through my old negatives and when I found my pictures from Poland, I decided I had to scan the gravestone images and turn them into an article. There are a few books on the subject of Jewish gravestone symbols, but not a whole lot online, which I suppose is why the article gets a lot of traffic.
Finding Information on US Immigrants is one of my favorite articles, and one I almost set up as a dedicated page like the page on naturalization records. In helping others with their genealogy, one of the big brick-walls people tend to run into, especially among American Jewish genealogists, is figuring out where their ancestors were from before coming to the United States. This article attempts to help people figure out where their family is from by looking at various resources that can provide clues, such as census records, passenger manifests, military draft cards, naturalization papers and historical newspapers. I think it’s the only article that I added a Table of Contents to, to make it easier to navigate quickly (as people can use it as a reference). The information in this article, combined with the US Immigrant Census Form I created, can really help people whose families came to the US in the several decades before and after the turn of the century to figure out where they originated.
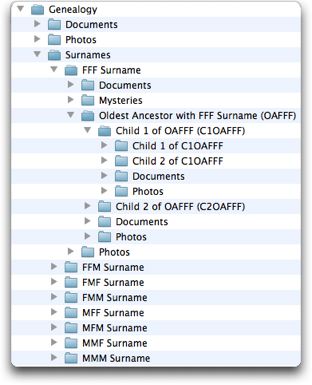
The last article among my top five is one about folder organization. It describes how I organize my genealogy files – what I call the B&F System. Everyone organizes their information differently, but this article describes how I try to keep track of images and documents connected to thousands of individuals. The key is being able to find exactly what you’re looking for quickly, and to be able to know what you have for every individual at a glance. No system is perfect, but my system is an attempt to minimize the many compromises that emerge when organizing so many files and folders.
Lectures
As mentioned earlier, I spoke in DC this past summer at the IAJGS International Conference on Jewish Genealogy, on the topic of Utilizing Belgian Archives for Jewish Research. In addition to that lecture, I’ve made a few other lectures here in Israel since starting this blog.
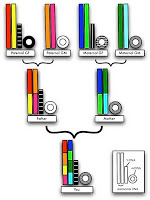
My first lecture was actually on the topic of genetic genealogy (The ABCs of DNA), which I gave in Ra’anana back in May. This lecture was based in part on my article Using DNA for Genealogy: Y-DNA and mtDNA, although the lecture also included a discussion of using Autosomal DNA for genealogy, but I still haven’t written an article on that topic. I gave a version of that same lecture in Modi’in (where I live) the next month with Richard Gussow, whose personal genetic genealogy success story added a very important personal touch to the lecture. Like the nice color diagram of DNA inheritance?
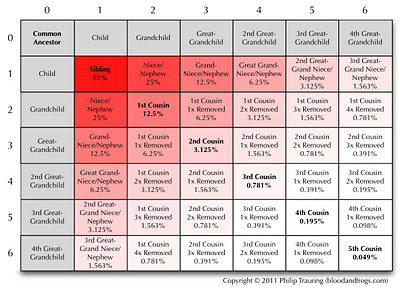
Speaking of diagrams (I think visually, so I like making diagrams) I recently published my own version of the famous cousin calculator table in my somewhat philosophical discussion of Perceptions of Relationship, where I try to see if how we perceive our relationship to our cousins match with an objective measure (percentage of shared DNA).
Another topic I recently lectured on twice is Preserving Family Photographs: Physical and Digital. That lecture is based in part on my article from back in January, Preserving Photographic Prints, Slides and Negatives, but also adds information on scanning photos and options for backing up your digital files. I gave this lecture last week in Jerusalem, and this week in Modi’in. A good overview of how to start with drawers full of photos and slides and organize them, place them in archival sheets and binders, and then digitize everything and back everything up. Perhaps this will make it into a screencast one day if I get around to doing screencasts – it’s on my list.
Social Networks
One of the more interesting aspects of blogging isn’t the blogging at all, but connecting to others through social media. Before I started blogging, I used Twitter passively as a way to follow news I was interested in, not to send anything. When I started blogging I quickly moved to using Twitter more actively, both to follow other genealogy bloggers, but also to promote my blog articles. Over the past year I’ve added 265 followers on Twitter (twitter.com/bloodandfrogs). Over 150 people subscribe to the blog via e-mail. Facebook, however, is where I have the most followers, with over 2500 fans (facebook.com/jewishgenealogy). Facebook is also where I am able to interact more directly with my readers, answering questions and helping people with their research if I can.
Another kind of social network is geneabloggers. A social network is, after all, just new-fangled name for a community. Geneabloggers, with Thomas MacEntee at the helm, has really helped create a community between the many people out there that blog about genealogy. Many thanks (and complete awe at how he does everything in a 24-hour day) to Thomas for working so hard to build and old-school social network among genealogy bloggers.
What’s Next?
It’s been a busy year, and I really have no idea what will be coming up in the next year.
Many genealogy blogs are about the person’s personal genealogy. I have specifically tried to avoid discussing my own genealogy in the blog, however, as my goal was always to provide information that others would find useful in their own genealogy. I think maybe this year I will include more of my family research as a way to explain how I found certain pieces of information, on the hope that others will be able to replicate the techniques I used. In the end, however, tomorrow is promised to no one, and we’ll have to wait and see…
For those of you who follow genealogy blogging, you probably recognize most if not all of those names. After seeing the series start I jokingly asked Jennifer on Twitter, why no Geneadaddybloggers? To which of course, Jennifer put me on the spot and asked me to write a guest post as well. I don’t think I fit into the list of other bloggers (and not just because of the Y chromosome) but I did write something, which you can read on her blog: Philip Trauring – How He Does It – Secrets from a Geneadaddyblogger. So give it a read and let me know what you think. Post comments to the original article on Jennifer’s site so everyone who reads the article can read them.
When you do research into your family, you need to cite your sources. Without sources for all the names, dates, etc. that you put into your family tree, your tree doesn’t really mean that much. Let me explain why this is the case.
There are millions of people worldwide who are actively researching their family trees. Some people consider it an occasional hobby, and others spend all their waking days looking into their families. No matter which side a researcher finds themselves on, or anywhere in between, the quality of the research done by these people varies greatly. In other words, some people do quality research, back up everything they find, and cite the sources for everything so they can go back and tell you how they determined the year a particular person was born, or what their name was before immigrating to the US, etc. Other people do lower-quality research, don’t record where they found anything, and just enter the names and dates they find into a database on their computer, or directly to an online family tree. I would venture to guess that there is little correlation between how much time someone spends on their family tree, and whether people are quality researchers or just name collectors.
So why is it a problem to just collect names and dates and throw them into a database? Well, primarily the problem is that you will make mistakes. I don’t mean that quality researchers don’t make mistakes and sloppy researchers do make mistakes – I mean everyone makes mistakes. There will always be times when you find a record of a person and you think it is the brother of so-and-so or the father of this-or-that cousin, and it really isn’t.
A good researcher will cite the source for the record, and most likely recognize that without more information they cannot conclusively say that the person is who they think it is. The good researcher might not even put the person into their tree, but put them in a folder for unconfirmed relatives until such time that they do find more information. If you don’t cite where you found out a piece of information, then when you do find more information, you will have no way to compare your new information with the old information.
For example, if you first calculated the birth year of a person by their age listed on their grave, but later find another record with the birth year on it, how will you know the relative strength of the new record versus the old record in terms of determining the birth year. Will you remember ten years later that you determined the age from a gravestone? What happens if you ended up recording the age of the wrong person? How would you confirm that without knowing your original source? Maybe you recorded the name of the person’s niece of nephew that shared the same name. How would you be able to tell?
Imagine a researcher just records names and dates as they find them. They don’t double-check anything, and couldn’t if they tried since they don’t know where their information originated. Using an example where someone recorded a nephew instead of the uncle, let’s say that same person finds a tree of the nephew online (which they identify since the spouse is the same). They copy and paste the new information into their tree, except it’s under the uncle instead. Now you have a branch of the family which is completely wrong. What does this researcher do next? They post their tree online with no sources. The next person comes along and finds someone who matches in their tree and copies the rest of the tree into their own, propagating the mistake.
There are really two lessons to be learned here.
First, don’t trust anything you find on the Internet, without independent confirmation. If you import a tree from a web site, make sure to check it out first.
Second, cite the source for everything you record in your own family tree, so you won’t come back years later with a new, different, piece of information and not know which is correct.
How To Cite Sources
When you were in high school or college you probably remember having to format your sources according to a citation style guide like the Chicago Manual of Style or the MLA Handbook. These guides defined where the title of the book or article went, how the author’s name was listed, etc. with examples for different types of citations – like newspaper articles, published books, unpublished dissertations, etc.
In the world of genealogy, there are many more types of evidence that one might need to cite in their research, since a scribble on the back of a an old photo, a listing in a commercial online database, the inscription of a gravestone, vital records of all kinds from all countries, etc. can be cited – all for the same person. The bible of genealogical citation is Elizabeth Shown Mill’s Evidence Explained. The book contains over a thousand citation models for just about any source you can think of that you will come across in your genealogy research. For example, do you know how to cite this blog entry? According to Evidence Explained (pg. 812) it could be formatted something like this:
Trauring, Philip, “Don’t Trust What You Find on the Internet, and Cite All Your Sources,” Blood and Frogs: Jewish Genealogy and More, 27 February 2011 (http://www.bloodandfrogs.com/2011/02/dont-trust-what-you-find-on-internet.html : accessed 27 February 2011)
It gives a two more options for different types of blog citations. It also has citation models for tweets, chats, discussion forums, podcasts and other Internet-based content that probably wasn’t listed in the MFA Handbook or Chicago Manual of Style the last time you used one of them. I’m pretty sure that even today you won’t find a citation model for citing a gravestones in the Chicago Manual of Style. Coming in at over 800+ pages, Evidence Explained is a much bigger book than those other style guides.
There has been an effort by some to try to standardize genealogy citation models around those in Evidence Explained, and indeed some genealogy software programs have offered the ability to use Evidence Explained citation models when citing sources in your program. I think that it’s good to have a standard for citations, and I hope all the major genealogy software companies adopt Evidence Explained as their citation model. If there isn’t a standard for citations, then sharing citation between programs becomes difficult.
The Debate
While there is no debate in the world of genealogy that there is a need to cite sources, there is a big debate over how to cite sources. Do you really need to follow strict citation standards like those advocated by Evidence Explained? Therein lies the issue debated amongst genealogists, how important is it really to use a citation model? Isn’t it just important to convey the information to find the source cited? Do you really need to follow an 800+ page book explaining every possible citation model you could need?
I’m not going to go into this debate in depth. I’m simply going to give my opinion that as long as you convey the correct information in an understandable way, the style is not really important. I think it’s great to use a system like Evidence Explained if you can, but if there’s a chance you won’t enter the source because it takes too long to figure out the right citation model for the source and you think you’ll get back to it later (which you won’t) then just enter the citation however you want. As genealogy programs add better source citation tools, this won’t become as big an issue and it will actually be easier to cite them properly when it is automated.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.