I’d like to thank the hundreds of people who viewed my session (Using the B&F Compendium of Jewish Genealogy) during the three-day Rootstech Connect Conference. The session will be available until next year’s conference, so if you missed it you can still watch it. As the conference itself is over now, I am directly linking to the video here. If you do like the video, you can still go to the Rootstech session page and like it by clicking the thumbs up button. You can watch the video on this page, or click on the title to load it in YouTube, where it should show up larger.
I am speaking at Rootstech Connect (February 25-27), the online conference sponsored by FamilySearch, that has over 500,000 registered attendees. Rootstech started out as a conference focused on the convergence of genealogy and technology, but over the past ten years has become the largest genealogy conference of any kind worldwide. This year’s conference is only online, and will be by far the biggest genealogy conference ever held.
I will be speaking about how best to utilize this site , in particular the B&F Compendium of Jewish Genealogy (the link is available now: Using the B&F Compendium of Jewish Genealogy). Like most of the lectures, mine will be available as video-on-demand, so you can watch it anytime during the 3-day conference, and should also be available for the next year online.
Ten years ago today, I posted my first article on this site, then a blog on Google’s Blogger platform. The post itself was thinking aloud about whether to switch genealogy programs from Reunion 9 to Family Tree Maker, which had just been introduced on the Mac for the first time (in case you’re wondering what I decided back then, I’m using Reunion 13 now).
One of the first things I always recommend to those getting started in genealogy is to collect as many family photographs as possible, from the oldest relatives you know, and try to identify everyone in the photographs. There may be a time that you won’t be able to ask who the people in your family photos are, and if you don’t find out who has old family photos, they may end up being thrown out at some point. If you do have a photo, but no way to identify the person or person in the photo, there is an approach you can take that may help you to figure it out.
In one of my earliest posts (Genealogy Basics: Up, Down and Sideways) I describe why it’s important to track down collateral relatives, such as finding all the descendants of your oldest known ancestor. Besides building out your tree, these people may end up knowing more about your common ancestors than you do. Even a small piece of information, such as the town someone was born in, can help break down genealogical brick walls. Similarly, those distant relatives may actually have the same photograph you have, and they may know who is in it.
When I started collecting family photos, my grandfather gave me a set of three large glass slides that his uncle had given him. One slide had two photos on it, of the same family, one with them wearing hats, and one without hats. I had an idea of who was in those family photos, and later confirmed it. The other two slides were individual portraits of a man and a woman. I did not know who they were, and neither did my grandfather. This is what the negatives looked like:
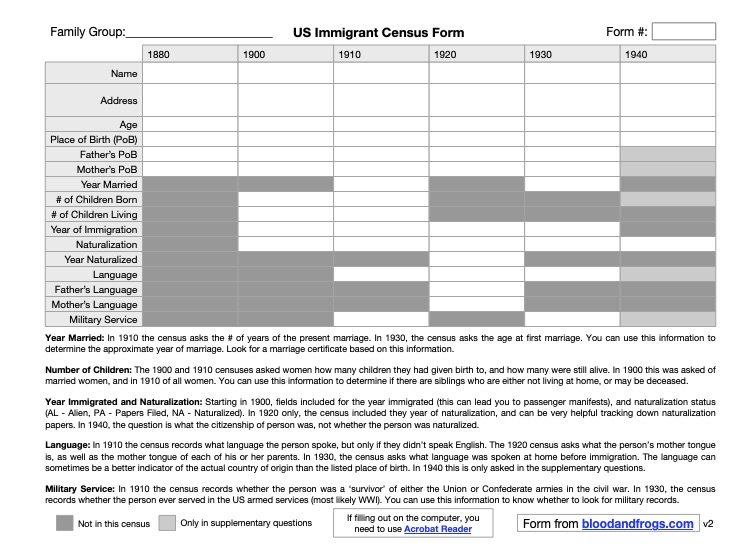
For those unaware, this site has a set of genealogy forms that you can fill out on a computer, or print out to be filled out by hand. I find this is a great way to get started with genealogy, and these forms are also helpful for sending out to relatives to be filled out and returned. These forms are designed to work together in useful ways. One form that is particularly useful is the US Immigrant Census Form, which was released all the way back in 2011. This form has fields for the useful genealogy information that you can extract from US Census records during the critical turn-of-the-century period of mass immigration to the US. When the original form was created, the 1940 Census had not yet been released, so it only covered the censuses between 1880 and 1930. This updated form adds a column for 1940.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.